

在今天早些時候的九月,Grafana 團隊公開預覽了他們全新的開源可觀測性工具專案「Grafana Beyla」。這是一款使用 eBPF 技術,捕捉服務中基本資訊以及 Linux HTTP/S 和 gRPC 相關指標提供可觀測性數據,並且不需要修改任何服務程式碼。
而在今年十一月的 ObservabilityCON 2023,Grafana 團隊介紹可觀測性領域的展望時,進一步的宣布 Beyla 1.0 的正式穩定版本到來。
Grafana Beyla,承襲著 Grafana 喜好北歐神話的命名習慣。
Grafana Beyla 基於 eBPF 的自動偵測,提供了簡潔有力的方法來實現服務的可觀測性,並且大大降低獲取底層遙測訊號的複雜門檻。
Grafana Beyla 使用 RED Method 指標來監控 HTTPS 和 gRPC 服務,對於 Web 服務或者說大多數的微服務有極高的價值,因為 RED Method 提供了衡量服務運作狀況、效率的重要資訊。透過 eBPF 技術可以自動檢查應用程式二進制檔案以及作業系統中的網路層互動,達到在核心層級運行並自動捕獲重要指標和追蹤的範圍,它可以讓我們更深入的了解應用服務之間的全貌,實現 Grafana 團隊所宣稱的 NoCode/ZeroCode 精神,而無須入侵現有程式碼也大大減低實施在生產環境的難度。
Grafana Beyla 1.0 目前支援多種程式語言,包括 Go、C/C++、Rust、Python、Ruby、Java(包括 GraalVM Native)、NodeJS 和 .NET 等。廣泛的支援度使其成為在不同程式環境中工作的開發人員的統一工具。
RED 指標的概念是由目前 Grafana 的 CTO Tom Wilkie ,在 Kausal 擔任創辦人時於 2015 年提出的。Wilkie 在意識到 USE Method 不適用於服務後創建了它。
在 RED Method 中,重點在於監視速率(每秒請求數)、錯誤(失敗的請求數)和持續時間(請求所花費的時間量)。
USE Method 旨在監視給定資源的利用率、飽和度和錯誤。
正如 Tom Wilkie 所說:RED 指標可以很好地反映客戶的滿意度。如果我們的錯誤率很高,那麼這基本上會傳達給用戶,他們會遇到頁面載入錯誤。如果我們的持續時間很長,那麼網站就會很慢。因此,這些都是建立有意義的警報和衡量 SLA 的非常好的指標。
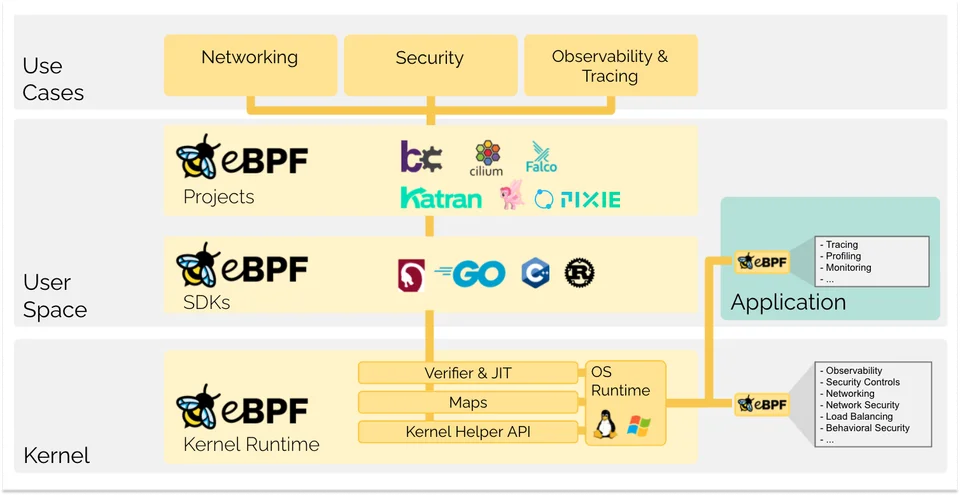
eBPF 代表的是「Extended Berkeley Packet Filter」,是一項革命性技術也是 BPF 的擴充(extended),起源於 Linux 內核,可以在特權上下文(privileged context)中運行沙盒程式。它用於安全有效地擴展核心的功能,而無需更改核心原始碼或載入核心模組。
如今,eBPF 被廣泛用於驅動各種用例:在現代資料中心和雲端原生環境中提供高效能網路和負載平衡,以極低的資源使用量去提取細顆粒的安全可觀察性數據,幫助應用程式開發人員追蹤應用程式,提供性能故障排除、預防性應用程式和容器運行時安全實施等方面的見解。
Grafana Beyla 是一款基於 eBPF 的 auto-instrumentation 工具,能夠追蹤服務端應用程式代碼的整體請求時間。
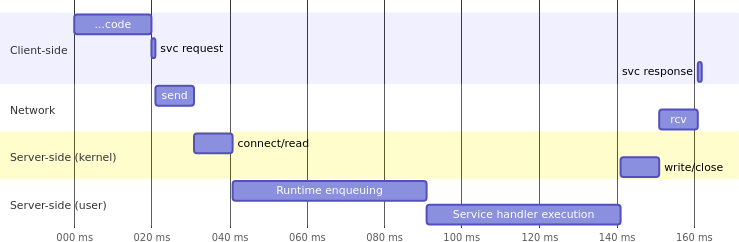
與服務處理時間相比,Client 端感知的實際回應時間與服務測量的請求回應不同。在 Web 服務請求的生命週期中,客戶端感知的回應時間接近於 140 毫秒。在 Server 端,大多數儀器化服務只能測量服務處理(Server handler execution)的時間,而 Server 端的其他執行時間則發生在內核或程式語言運行時。

在低負載條件下,大部分執行時間花在服務處理程序上,但在高負載情況下,許多請求可能在內部隊列中等待調度的時間不容忽視。僅儀器化服務處理程序可能導致報告的度量數據不準確,實際上在 Server 端花費了更多時間。
eBPF 允許我們克服手動儀器化工具的限制。Beyla 在內核的 connect / receive / write / close 函數中插入追蹤點。這種底層儀器化提供了更精確的度量和追蹤數據,更接近於用戶感知的響應時間。Beyla 報告的追蹤數據分為不同的階段,包括整體請求在 Server 端的時間、請求在隊列中等待的時間,以及請求處理程序(應用邏輯)實際花費的時間。
Note:我們可以由實戰演練的 Grafana Tempo 圖片中,查看 Grafana Beyla 所產生的 Span 所帶來的資訊。
Beyla可以作為獨立的 Linux 進程,在 Docker、Kubernetes 容器運行。並且在 Beyla 1.0 正式版本後支持了多進程,使我們在 Kuberentes 中可以將 Beyla 佈署為「 Daemonset」而不是比較重複消耗資源的「Sidecar」模式,這更使我們避免了更新 sidecar 時需要重啟服務的不便,大大的簡化了 Kuebernetes 的部署。
apiVersion: apps/v1
kind: Deployment
# ...
spec:
# Required so the sidecar instrument tool can access the service process
shareProcessNamespace: true
containers:
# Container for the instrumented service
- name: your_container_for_beyla
# ...
# Sidecar container with Beyla - the eBPF auto-instrumentation tool
- name: beyla
image: grafana/beyla:latest
securityContext: # Privileges are required to install the eBPF probes
privileged: true
env:
- name: BEYLA_OPEN_PORT
value: "8443"
# ...
sidecar container 主要概念為共享每個 main container 相同的生命週期、儲存空間、網路命名空間等。我們可以從 Grafana 官方提供的 Beyla sidecar 範例上看出,在此模式中使用 eBPF 技術通常需要以下配置需求:
shareProcessNamespace: true
securityContext.privileged: true
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: beyla
labels:
app: beyla
spec:
selector:
matchLabels:
app: beyla
template:
metadata:
labels:
app: beyla
spec:
hostPID: true # Required to access the processes on the host
containers:
- name: autoinstrument
image: grafana/beyla:latest
securityContext:
runAsUser: 0
privileged: true
# ...
在 Kubernetes 中佈署 Daemonset 資源,將會在 Kubernete 叢集中預設確保了每個節點都會運行指定的 Pod,非常適合作為收集整個叢集資源監控的資源負載選擇(如 Prometheus Node Exporter)。而我們也能使用 Beyla 監測到多個服務進程,甚至是叢集中所有可偵測的目標:
hostPID: true
不論是從 Beyla 的官方文件或相關文章中,可以注意到 Grafana 團隊除了設計架構良好的高效率工具之外,同時也將各種使用者會遇到的實務情景考慮到其中。
Grafana 團隊提到監控解決方案的關注重點之一始終是「成本」,收集和儲存這些應用服務遙測訊號需要花費多少成本?以及查詢這些資料需要多少資源?或許 Grafana 團隊不想限制使用者的資料使用情境,但仍在「基數爆炸」的監控成本議題下,不論是從 Url Path 或者是過濾收集服務對象,花費了很多心思設計,盡可能的確保我們只儲存必要的數據。例如,HTTP URL 路徑設計上常見的動態路徑:/users/{id}(像/users/123 /users/456 ),就隱藏著基數爆炸的風險。
接下來在我們進行 Demo 範例前,先來看看 Beyla 的基本相關設定。
# /usr/local/bin/language-server
# /opt/app/server
executable_name: server
open_port: 80,443,8000-8999
discovery:
services:
- exe_path_regexp: (worker)|(backend)|(frontend)
open_port: 80,443
namespace: MyNamespace
name: MyApplication
我們應該盡可能routes屬性來減少產生的指標的基數。
routes:
patterns:
- /user/{id}
- /user/{id}/basket/{product}
ignored_patterns:
- /health
- /v1/*
ignore_mode: all
unmatched: wildcard
http.route 相應地設定追蹤 / 指標屬性,而 ignored_patterns 可以忽略匹配的 URL Pattern。/**。Note:關於 Grafana Beyla 的 Routes decorator 模式,可以說是整個服務的關鍵核心。
其中濃縮了基數、抽樣、資料格式、可觀測性策略等多種概念,強烈建議細細品味其官方文件。
現在我們將要實際運作起 Grafana Beyla 1.0 的相關範例以及 Prometheus 和 Grafana,作為收集及展示數據的工具,幫助理解 Beyla 提供的各種參數以及設計概念。
我們將利用先前建立好的 Kube-Prometheus-Stack 來作為 Grafana 與 Prometheus 的可視化介面,其中詳細安裝過程可以回頭複習一下「Kube-Prometheus-Stack 實戰系列」。
$ helm upgrade --install prometheus-stack prometheus-community/kube-prometheus-stack --values=values.yaml -n prometheus --create-namespace
Release "prometheus-stack" does not exist. Installing it now.
NAME: prometheus-stack
LAST DEPLOYED: Tue Nov 7 00:19:09 2023
NAMESPACE: prometheus
STATUS: deployed
REVISION: 1
NOTES:
kube-prometheus-stack has been installed. Check its status by running:
kubectl --namespace prometheus get pods -l "release=prometheus-stack"
Visit https://github.com/prometheus-operator/kube-prometheus for instructions on how to create & configure Alertmanager and Prometheus instances using the Operator.
相關設定檔同步收錄在文章底部的 Github 連結。
同樣的,我們也將利用 Grafana Tempo 當作分散式追蹤的後端儲存服務,詳細安裝過程可以複習「Grafana Tempo 實戰系列」。
$ helm upgrade --install tempo grafana/tempo-distributed -n tracing -f values.yaml --create-namespace
Release "tempo" does not exist. Installing it now.
NAME: tempo
LAST DEPLOYED: Tue Nov 7 00:22:23 2023
NAMESPACE: tracing
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
***********************************************************************
Welcome to Grafana Tempo
Chart version: 1.6.9
Tempo version: 2.2.3
***********************************************************************
Installed components:
* ingester
* distributor
* querier
* query-frontend
* compactor
* memcached
* gateway
相關設定檔同步收錄在文章底部的 Github 連結。
$ kubectl apply -f https://raw.githubusercontent.com/honeycombio/example-greeting-service/main/go-uninstrumented/greetings.yaml
---
serviceaccount/frontend-go created
service/frontend created
deployment.apps/frontend-go created
serviceaccount/message-go created
service/message created
deployment.apps/message-go created
serviceaccount/name-go created
service/name created
deployment.apps/name-go created
serviceaccount/year-go created
service/year created
deployment.apps/year-go created
這裡我們使用 honeycomb.io 提供的輕量的 Golang 微服務當作範例。
隨後我們可以將此微服務接口導出,並且產生一些相關請求當作監控指標以及追蹤訊號:
kubectl port-forward svc/frontend 8000:7777
接下來即可透過 localhost:8000/greeting 模擬微服務互動製造假資料。
# daemonset.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: beyla
labels:
app: beyla
instrumentation: beyla
spec:
selector:
matchLabels:
instrumentation: beyla
template:
metadata:
labels:
instrumentation: beyla
spec:
serviceAccountName: default
hostPID: true # important!
# mount the ConfigMap as a folder
volumes:
- name: beyla-config
configMap:
name: beyla-config
containers:
- name: beyla
image: grafana/beyla:latest
imagePullPolicy: IfNotPresent
securityContext:
privileged: true # important!
command: ["/beyla", "--config=/config/beyla-config.yml"]
ports:
# expose the metrics ports
- containerPort: 8999
name: metrics
- containerPort: 8990
name: internal
volumeMounts:
- mountPath: /config
name: beyla-config
# configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: beyla-config
data:
beyla-config.yml: |
print_traces: true
log_level: debug
open_port: 80-8999
otel_traces_export:
endpoint: http://tempo-distributor.tracing:4317
prometheus_export:
port: 8999
path: /metrics
report_target: false
report_peer: false
internal_metrics:
prometheus:
port: 8990
path: /metrics
routes:
ignored_patterns:
- /metrics
- /health
unmatched: heuristic
利用 Configmap 將 beyla 設定檔拆開來管理。設定了相關 Prometheus 監控服務端點,並且將追蹤訊號傳送到我們建立的 Grafana Tempo 服務中,並且使用了 heuristic 來顯示 Url Path 在數據當中,而不是只能得到 /** 的數值。
接下來就來建立起 Grafana Beyla 資源:
$ kubectl apply -f configmap.yaml,daemonset.yaml
configmap/beyla-config created
daemonset.apps/beyla created
還記得我們在上面 Config 設定中暴露出來的 Prometheus 端點嗎?此資訊正是官方所強調的 RED Method 指標的來源依據,所以我們現在需要利用 Podmonitor 使 Prometheus Server 可以主動 Pull Beyla 的監控指標,並且建立 RED Dashboard 可視化監控。
# pod-monitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: beyla-podmonitor
labels:
release: prometheus-stack
spec:
selector:
matchLabels:
instrumentation: beyla
podMetricsEndpoints:
- port: metrics
接下來就來建立起 Prometheus CRDs podmonitor 資源:
kubectl apply -f pod-monitor.yaml
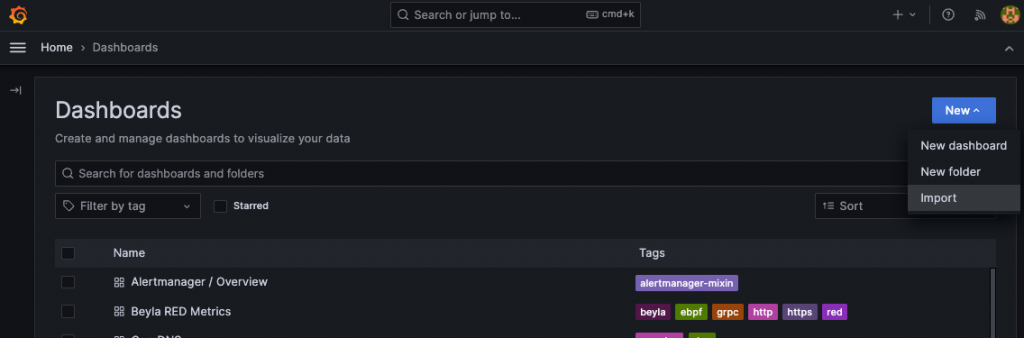
在 Grafana Dashboard 主頁點擊 Import 進入 Import 頁面。
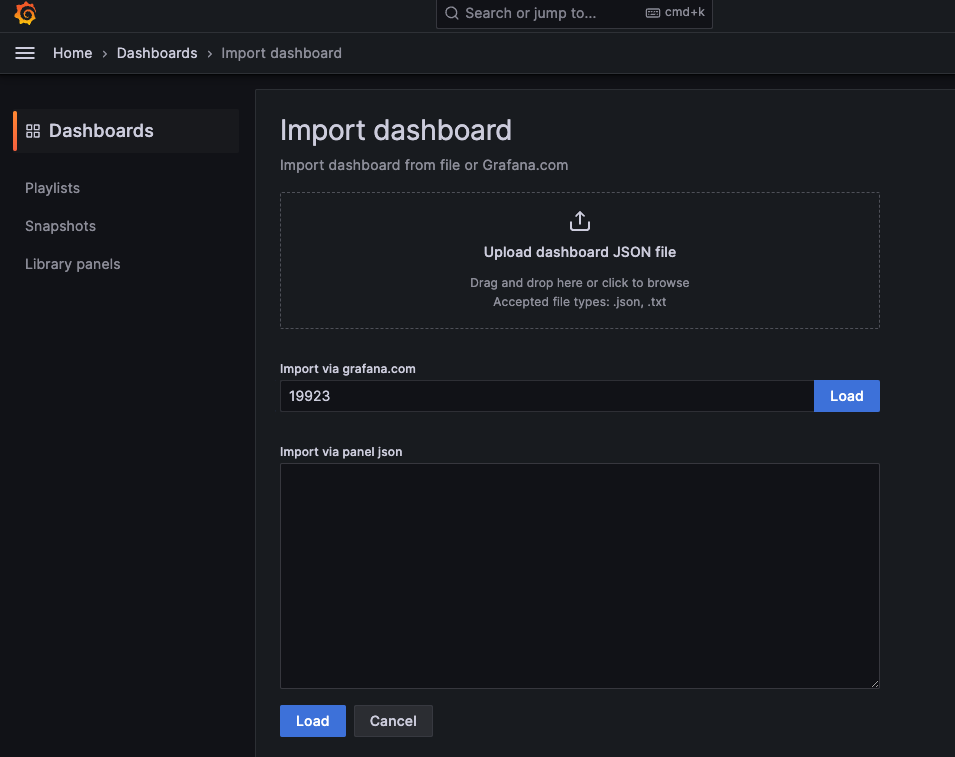
輸入 dashboard id:19923 即可載入最新官方 Beyla RED Metrics Dashboard。
首先讓我們將 Grafana 端點導出來:
kubectl port-forward service/prometheus-stack-grafana 3100:80 -n prometheus
------
Forwarding from 127.0.0.1:3100 -> 3100
Forwarding from [::1]:3100 -> 3100
接著進入我們本機中的 localhost:3100 就能看到精美的 Grafana Login 頁面。
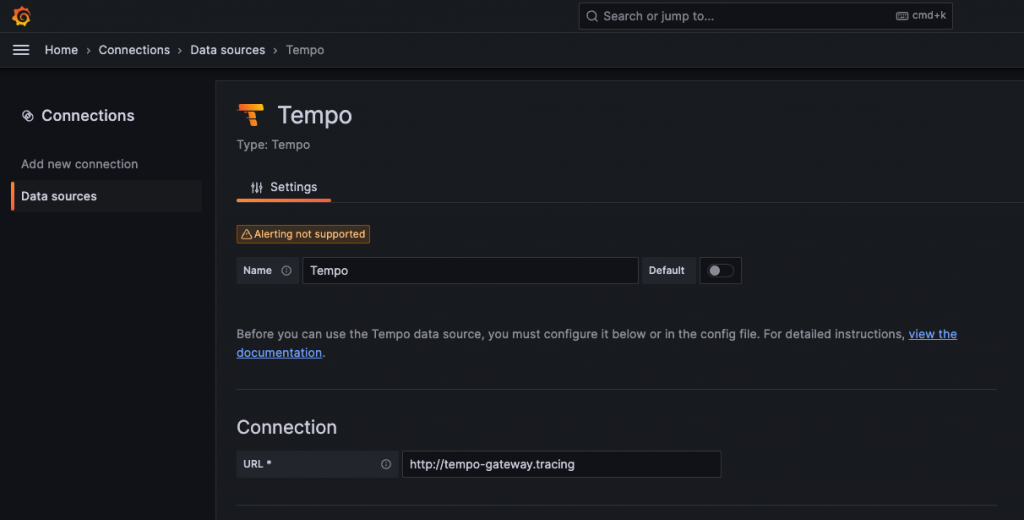
現在我們就在 Data Sources 中將我們的 tempo-gateway 或 tempo-query-frontend 查詢組件的端點新增到 Grafana 上。
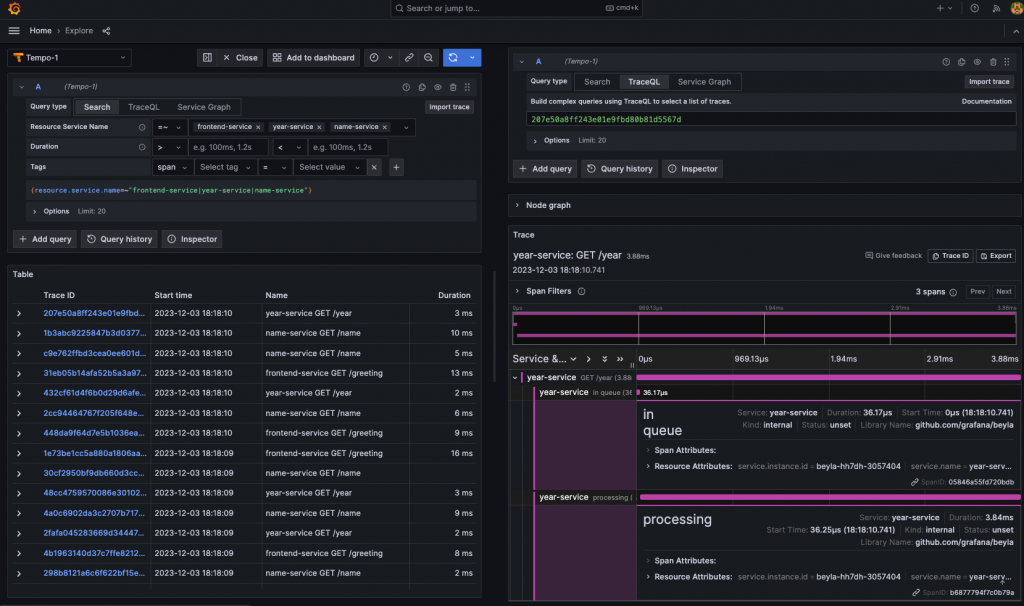
經歷一番功夫,我們終於可以在 Grafana Tempo 中看到 Beyla 利用 eBPF 蒐集到的微服務「總請求時間」的追蹤訊號,也讓我們可以得知每個請求在進入「processing」階段前,處於「in queue」狀態耗費了多少時間。
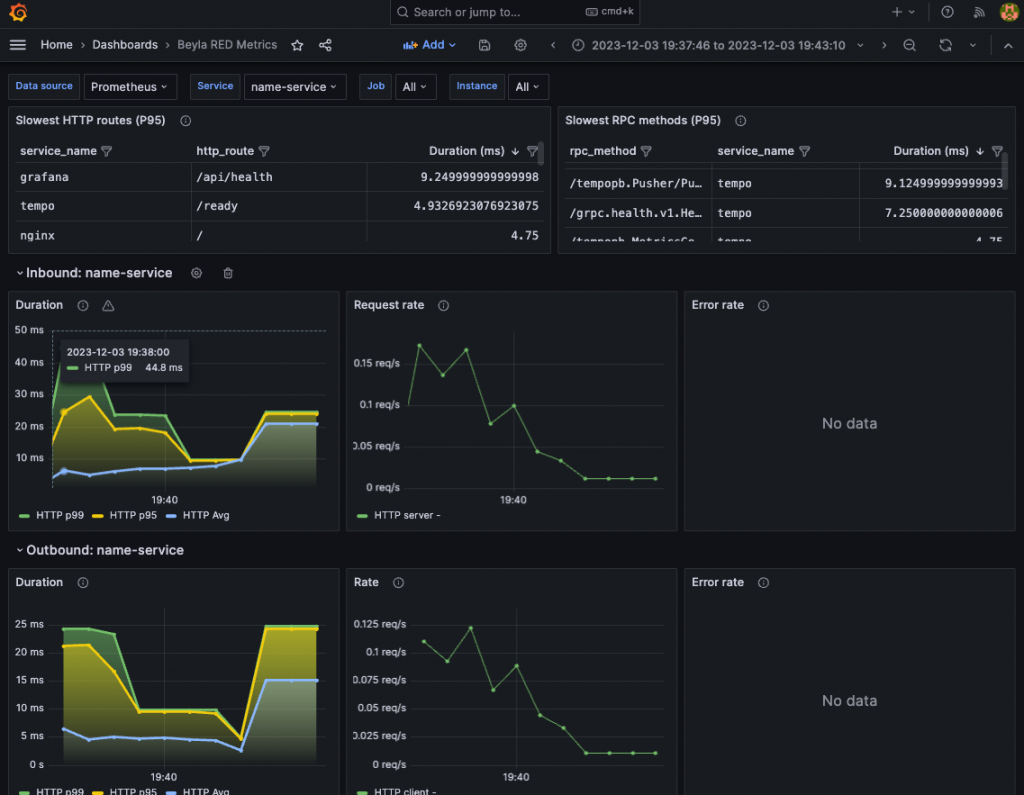
從目前 Grafana 團隊官方提供的 Dashboard 中,我們可以看到以下部分:
Note:更多高整合度的 Grafana Beyla 資料展示,目前還只在 Grafana Cloud 上才看得到,相信不遠的未來會慢慢釋出到 OSS 版本中。
在認識市面上主流的分佈式追蹤工具後,有了像 Opentelemetry SDK/Auto-instrumentation、Jaeger 以及 KeyVal Odigos 先入為主的觀念後,一開始的我也很自然而然的認為,Grafana Beyla 是一款跟 Opentelemetry Auto-instrumentation 一樣,透過 eBPF 技術在 Kernel 中捕捉每個分佈式服務的請求進而產生追蹤訊號。沒想到雖然都是使用 eBPF 技術,卻竟然是完全不同層面的工具,而 Grafna Beyla 是無入侵的方式可以在短時間內建立,追求更極致細膩的 RED 指標加以利用,這也使我們對 eBPF 技術的強大有更深一層的認識。
在官方談到對 Beyla 的展望時,也對實現分佈式追蹤抱持樂觀開放性的看法。畢竟在我們上面的範例中,Grafana Beyla 只是很單純的收集並展現 RED 指標的應用,還沒有展現出 eBPF 生態真正的威力。同時 Grafana 團隊也在針對 Kubernetes 與 Opentelemetry 加入更多支援功能(像 kubernetes decorator),可以看出不僅是 Grafana 團隊,整個社群都還在摸索可觀測性領域的最大可能性,那可是最令人期待的。
相關程式碼同步收錄在:
https://github.com/MikeHsu0618/grafana-stack-in-kubernetes/tree/main/day32
Referrences:
Grafana Beyla Provides Auto-Instrumented Observability through eBPF
Cloud Native Digest: Grafana Beyla released
Reviewing eBPF-based auto-instrumentation with Grafana Beyla
Open source ebpf auto-instrumentation with Grafana Beyla
What is eBPF? An Introduction and Deep Dive into the eBPF Technology


 iThome鐵人賽
iThome鐵人賽